新增内容AI 共创
AI播客:大模型上下文窗口:AI“记忆”的长度与力量
什么是上下文窗口(Context Window)
上下文窗口(Context Window)是大型语言模型(LLM)在处理单次请求时能够"看到"和"记住"的最大文本长度。
它决定了模型能够同时处理多少信息,是衡量 LLM 能力的重要指标之一。
核心概念
预计阅读时间: 7 分钟什么是上下文?
在 LLM 中,"上下文"包括:
- 用户的输入(Prompt)
- 模型的历史回复
- 系统提示词(System Prompt)
- 所有先前的对话记录
示例:
如果上下文窗口 = 4K,还剩余 1640 token 用于模型回复。
Token 与字符的关系
- 英文:1 token ≈ 4 个字符 ≈ 0.75 个单词
- 中文:1 token ≈ 1-2 个汉字
- 代码:1 token ≈ 1-2 个字符(取决于编程语言)
快速换算:
| Token 数 | 英文单词数 | 中文字数 |
|---|---|---|
| 1K | ~750 | ~1000 |
| 4K | ~3000 | ~4000 |
| 8K | ~6000 | ~8000 |
| 32K | ~24,000 | ~32,000 |
| 128K | ~96,000 | ~128,000 |
| 1M | ~750,000 | ~1,000,000 |
上下文窗口的限制
1. 硬性限制
超过上下文窗口的内容会被截断:
2. 注意力衰减
即使在窗口内,距离越远的内容,模型"记住"的能力越弱。
这被称为"Lost in the Middle"现象:
- 开头的内容:记得很清楚
- 中间的内容:容易忽略
- 结尾的内容:记得很清楚
实验结果:
3. 计算成本
注意力机制的计算复杂度是 O(n²):
- 上下文长度翻倍 → 计算量增加 4 倍
- 128K 的计算量是 4K 的 1024 倍
这导致:
- 响应时间更长
- 成本更高(API 按 token 计费)
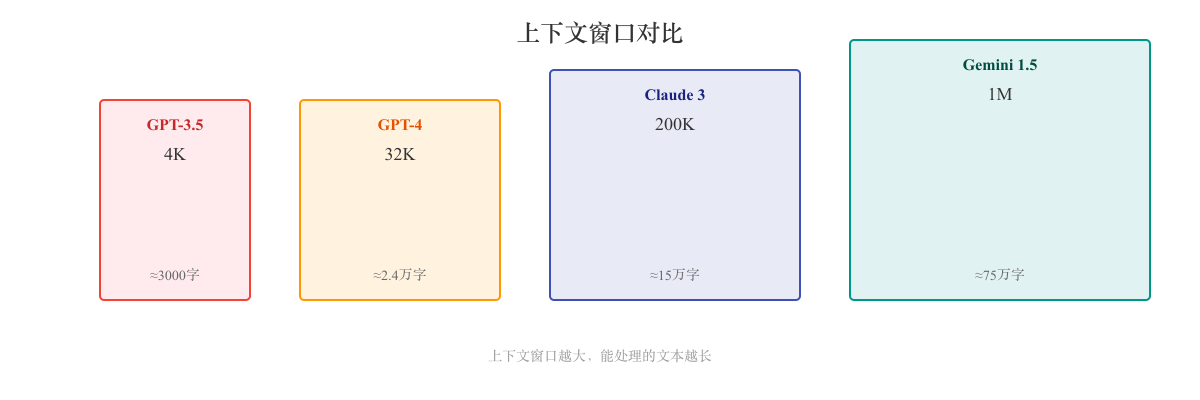
主流模型的上下文窗口
2023 年之前(小上下文时代)
| 模型 | 上下文窗口 | 发布时间 |
|---|---|---|
| GPT-3 | 2K-4K | 2020 |
| GPT-3.5 | 4K | 2022 |
| ChatGPT | 4K | 2022.11 |
2023-2024(中等上下文)
| 模型 | 上下文窗口 | 发布时间 |
|---|---|---|
| GPT-4 | 8K/32K | 2023.03 |
| GPT-4 Turbo | 128K | 2023.11 |
| Claude 2 | 100K | 2023.07 |
| Claude 3 | 200K | 2024.03 |
2024-2025(超长上下文)
| 模型 | 上下文窗口 | 发布时间 |
|---|---|---|
| Gemini 1.5 Pro | 1M (100万) | 2024.02 |
| Gemini 1.5 Flash | 1M | 2024.05 |
| Claude 3.5 Sonnet | 200K | 2024.06 |
| GPT-4o | 128K | 2024.05 |
| Qwen3 | 1M | 2025.01 |
1M token 能装多少内容?
- 约 75 万英文单词
- 约 100 万汉字
- 相当于:
- 4-5 本长篇小说
- 整个代码库(中小型项目)
- 数十份 PDF 文档
长上下文的技术挑战
挑战 1:计算效率
解决方案:
- Flash Attention:优化注意力计算,降低内存占用
- Sparse Attention:只关注部分重要 token
- Grouped Query Attention (GQA):减少 KV Cache 大小
- Sliding Window Attention:只关注局部窗口
挑战 2:位置编码外推
模型训练时的序列长度有限,如何外推到更长序列?
解决方案:
- RoPE(旋转位置编码):天然支持外推
- ALiBi:线性偏置,无需位置编码
- YaRN:改进 RoPE 的外推能力
- Dual-Chunk Attention:Qwen3 用于支持 1M 上下文
挑战 3:"Lost in the Middle"
模型容易忽略中间部分的内容。
解决方案:
- 改进训练数据(确保模型关注全文)
- 使用 Retrieval(检索重要片段,而非全文输入)
- 提示词工程(将重要信息放在开头或结尾)
实际应用场景
短上下文(4K-8K)适用场景
- ✅ 日常对话
- ✅ 简单问答
- ✅ 短文本翻译
- ✅ 代码片段生成
中等上下文(32K-128K)适用场景
- ✅ 文档总结(10-50 页)
- ✅ 代码审查(单个文件或小模块)
- ✅ 长对话历史
- ✅ 论文分析
超长上下文(1M)适用场景
- ✅ 整本书总结
- ✅ 整个代码库分析
- ✅ 长时间对话(数小时)
- ✅ 批量文档处理
如何优化上下文使用
1. 提示词压缩
2. 使用总结功能
对于长文档,先总结再提问:
3. 结合 RAG(检索增强生成)
不把整个文档塞进上下文,而是:
- 检索相关片段
- 只把相关部分送入模型
这样即使文档很长,也不占用太多上下文。
4. 滚动窗口(Sliding Window)
对于超长对话,只保留最近的 N 条消息:
成本考虑
不同上下文窗口的价格差异巨大:
示例(OpenAI GPT-4 定价):
| 模型 | 上下文 | 输入价格($/1M tokens) | 输出价格($/1M tokens) |
|---|---|---|---|
| GPT-4 | 8K | $30 | $60 |
| GPT-4 Turbo | 128K | $10 | $30 |
实际计算:
未来趋势
1. 无限上下文?
理论上可行,但实际挑战:
- 计算成本过高
- 信息检索效率低
- 并非所有任务都需要
2. 混合方案
- 短上下文模型:处理简单任务(便宜、快速)
- 长上下文模型:处理复杂任务(昂贵、慢速)
- 检索系统:只提取相关信息(节省上下文)
3. 更高效的架构
- Mamba:线性复杂度的序列模型
- RWKV:结合 RNN 和 Transformer 优势
- Hyena:次二次复杂度的注意力机制
常见问题
Q: 上下文窗口越大越好吗?
A: 不一定。
- 成本更高
- 速度更慢
- 对于简单任务,小上下文足够
Q: 如何知道自己的输入有多少 token?
A: 使用 Tokenizer 工具:
- OpenAI:tiktoken
- 在线工具:OpenAI Tokenizer
Q: 上下文窗口和模型参数量有关系吗?
A: 没有直接关系。
- 7B 参数的模型可以有 1M 上下文(如 Gemini 1.5 Flash)
- 175B 参数的模型可能只有 4K 上下文(如 GPT-3)
关键在于架构设计和训练方法。
参考资料
目录