什么是 Temperature 和采样策略
采样策略(怎么"掷骰子"):
除了 Temperature,还有其他"掷骰子"的方法:
1. Top-k(只看前 k 个)
- 只从"前 k 个最有可能的词"里选
- 例如 k=5:只从前 5 个候选词里选,其他全忽略
- 好处:避免选到太离谱的词
- 坏处:可能漏掉好答案
2. Top-p(核采样,只看概率和 ≥ p 的)
- 从"概率总和达到 p"的最小词集里选
- 例如 p=0.9:选最有可能的词,直到累计概率 ≥ 90%
- 好处:动态调整候选词数量(有时 3 个词就够 90%,有时需要 20 个)
- 坏处:计算稍复杂
3. 贪心采样(Greedy,永远选最好的)
- 每次都选概率最高的词
- = Temperature 0
- 好处:确定性强
- 坏处:无趣
实际应用场景:
需要准确答案(Temperature ≈ 0):
- 数学题:"1+1=?"
- 代码生成:"写个快速排序"
- 翻译:"Translate: Hello"
- 事实查询:"秦始皇哪年统一六国?"
需要平衡创意(Temperature ≈ 0.7):
- 聊天对话
- 写邮件
- 文章总结
- 常见的对话助手(ChatGPT 默认)
需要创意爆棚(Temperature ≈ 1.0-1.2):
- 写小说
- 头脑风暴
- 创意文案
- 写诗、写歌词
千万别用高温(Temperature > 1.5):
- 基本只会胡说八道
- 除非你故意要搞笑
常见参数组合:
保守型(适合严肃场景):
平衡型(默认推荐):
创意型(写作、脑暴):
极度保守(代码、数学):
打个比方:
Temperature 就像"喝酒的度数":
- 0 度:完全清醒,一板一眼
- 0.7 度:微醺,有点放松但还理智
- 1.5 度:喝高了,开始说胡话
- 2.0 度:喝多了,完全不知道自己在说啥
说白了,Temperature 和采样策略就是控制 AI 的"随机性"——严肃场景调低(0-0.3),创意场景调高(0.7-1.2),千万别爆表(> 1.5)。
预计阅读时间: 10 分钟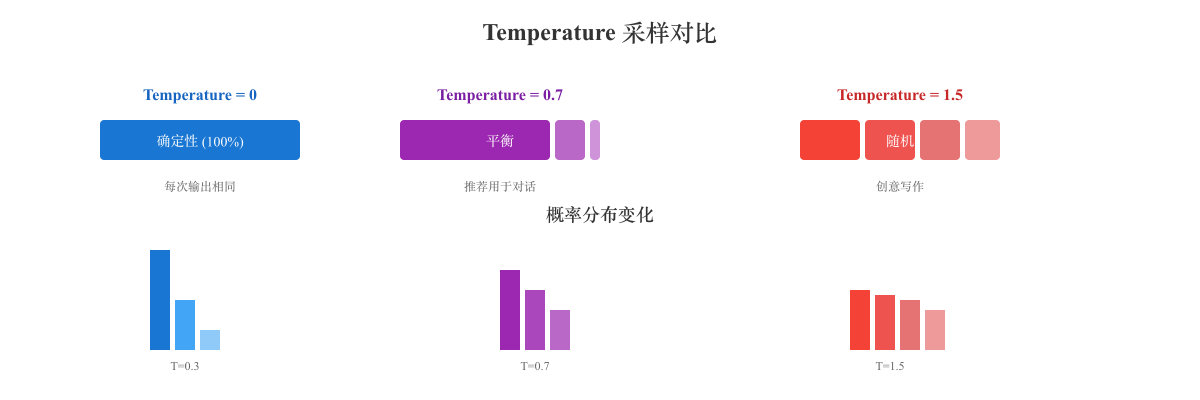
Temperature 和采样策略是控制大型语言模型(LLM)生成文本随机性和创造性的核心参数。
理解这些参数对于优化 AI 输出质量至关重要。
核心概念:模型如何生成文本
生成流程
LLM 生成文本是一个逐词预测的过程:
模型需要从这个概率分布中选一个词,这个选择过程就是采样(Sampling)。
确定性 vs 随机性
确定性输出(Deterministic):
- 每次都选概率最高的词
- 相同输入 → 相同输出
- 适合:数学题、代码、翻译
随机性输出(Stochastic):
- 按概率随机选词
- 相同输入 → 不同输出
- 适合:创意写作、对话、头脑风暴
Temperature(温度参数)
定义
Temperature 是一个缩放因子,用于调整概率分布的"陡峭程度"。
数学原理
在生成下一个 token 时,模型输出的原始分数(logits)通过 Softmax + Temperature 转换为概率:
Temperature 取值效果
| Temperature | 概率分布 | 输出特点 | 适用场景 |
|---|---|---|---|
| 0 | 完全确定 | 每次选最高概率的词 | 数学、代码、翻译 |
| 0.1-0.3 | 非常陡峭 | 几乎总是选最可能的,偶尔惊喜 | 事实性问答、摘要 |
| 0.5-0.7 | 较陡峭 | 平衡准确性和多样性 | 客服对话、邮件撰写 |
| 0.7-1.0 | 标准 | 既靠谱又有创意 | 通用对话(ChatGPT 默认) |
| 1.2-1.5 | 较平缓 | 创意十足,偶尔偏离主题 | 小说创作、头脑风暴 |
| > 1.5 | 非常平缓 | 高度随机,常常胡言乱语 | 几乎不可用 |
可视化示例
问题: "推荐一部科幻电影"
Temperature = 0(完全确定):
Temperature = 0.7(平衡):
Temperature = 1.5(高度随机):
采样策略(Sampling Strategies)
除了 Temperature,还有其他方法控制词语选择:
1. 贪心采样(Greedy Sampling)
规则: 每次选择概率最高的词
特点:
- ✅ 完全确定性(无随机性)
- ✅ 快速
- ❌ 输出单调,缺乏多样性
- ❌ 可能陷入重复("我觉得我觉得我觉得...")
等价于: Temperature = 0
适用: 翻译、代码补全、数学题
2. Top-k 采样
规则: 只从概率最高的 k 个词中随机选择
参数:
- k = 1:等价于贪心采样
- k = 5-10:保守,主要选高概率词
- k = 50-100:宽松,允许更多可能性
优点:
- ✅ 避免选到极低概率的"怪词"
- ✅ 保证基本质量
缺点:
- ❌ k 固定,不适应不同情况(有时 3 个词就够,有时需要 20 个)
- ❌ 可能错过合理的低频词
适用: 对话生成、内容创作
3. Top-p 采样(Nucleus Sampling,核采样)
规则: 选择累计概率达到 p 的最小词集
参数:
- p = 0.5:非常保守,只选最可能的几个词
- p = 0.9:平衡(常用值)
- p = 0.95:稍宽松
- p = 1.0:考虑所有词
优点:
- ✅ 动态调整候选词数量(适应不同情况)
- ✅ 在确定性和多样性之间取得平衡
缺点:
- ❌ 计算稍复杂
适用: 通用对话(ChatGPT 默认使用)
4. Top-k + Top-p 组合
最佳实践: 同时使用 Top-k 和 Top-p
好处:
- Top-k 排除极低概率词(避免"垃圾词")
- Top-p 动态调整范围(灵活性)
- Temperature 微调随机性(精细控制)
实际应用建议
场景 1:代码生成
原因:
- 代码需要精确性
- 不允许随机性(语法错误无法容忍)
示例:
场景 2:客服对话
原因:
- 需要准确回答用户问题
- 允许少量变化(避免机械感)
示例:
场景 3:通用对话(ChatGPT 风格)
原因:
- 平衡准确性和创造性
- 输出自然、不死板
示例:
场景 4:创意写作
原因:
- 需要创造性和惊喜
- 允许大胆的词汇选择
示例:
场景 5:数学/逻辑题
原因:
- 只有一个正确答案
- 任何随机性都是负面的
示例:
常见参数组合表
| 任务类型 | Temperature | Top-p | Top-k | 说明 |
|---|---|---|---|---|
| 代码生成 | 0-0.2 | - | 1-5 | 极度保守 |
| 翻译 | 0-0.3 | 0.9 | 10 | 准确为主 |
| 摘要 | 0.3-0.5 | 0.9 | 40 | 平衡 |
| 客服对话 | 0.5-0.7 | 0.9 | 50 | 友好但准确 |
| 通用对话 | 0.7 | 0.95 | - | ChatGPT 默认 |
| 创意写作 | 0.9-1.2 | 1.0 | - | 放飞自我 |
| 头脑风暴 | 1.0-1.3 | 1.0 | - | 创意优先 |
调试技巧
问题 1:输出太无聊
症状:
解决: 提高 Temperature(0.7 → 1.0)
问题 2:输出太离谱
症状:
解决: 降低 Temperature(1.5 → 0.7)
问题 3:输出重复
症状:
解决:
- 提高 Temperature(0 → 0.3)
- 使用 Top-p(0.9)
- 启用重复惩罚(Repetition Penalty)
问题 4:代码经常出错
症状:
解决: Temperature = 0(完全确定性)
API 调用示例
OpenAI API
Anthropic Claude API
本地模型(Hugging Face)
常见问题
Q: Temperature 和 Top-p 哪个更重要?
A: 都重要,但作用不同:
- Temperature:调整概率分布的"陡峭度"
- Top-p:过滤低概率候选词
建议:先调 Temperature,再微调 Top-p
Q: 为什么 ChatGPT 每次回答都不一样?
A: 因为 Temperature > 0,启用了随机采样。如果需要确定性,设置 Temperature = 0。
Q: Temperature > 1.0 有意义吗?
A: 理论上可以,但实际上:
- 1.0-1.2:还能用(创意写作)
-
1.5:基本胡说八道
Q: 如何让模型"更聪明"?
A: Temperature 不影响"聪明程度",只影响"随机性"。 要让模型更聪明,需要:
- 更好的提示词(Prompt Engineering)
- 更大的模型
- 微调(Fine-tuning)