新增内容AI 共创
AI播客:LLM炼成记:三阶段如何从知识储备变身实用助手
什么是预训练/监督微调/RLHF
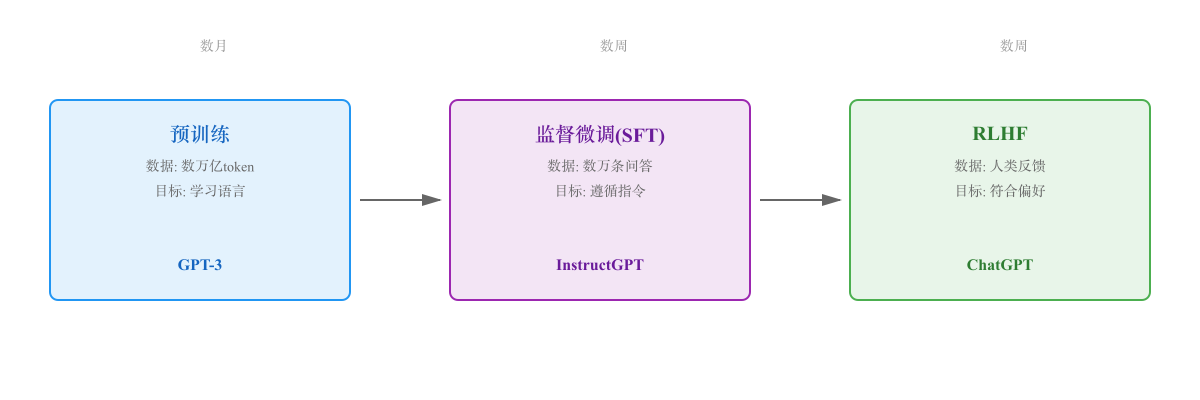
大型语言模型(LLM)的训练通常分为三个关键阶段:预训练(Pre-training)、监督微调(Supervised Fine-Tuning, SFT) 和 人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)。
这三个阶段构成了现代 LLM(如 ChatGPT、Claude、Gemini)从"知识储备"到"实用助手"的完整演化路径。
第一阶段:预训练(Pre-training)
预计阅读时间: 9 分钟核心目标
让模型学习语言的统计规律和世界知识,建立强大的语言理解和生成能力。
训练方式
自监督学习:无需人工标注,使用"预测下一个词"(Next Token Prediction)作为训练目标。
模型通过阅读海量文本(数万亿 token),学会:
- 语法规则
- 常识知识
- 推理能力(初步)
- 多语言能力
训练数据
- 来源:互联网爬虫、书籍、论文、代码、维基百科等
- 规模:数万亿 token(例如 GPT-3 用了 300B token,LLaMA 2 用了 2T token)
- 质量控制:去重、过滤低质量内容、移除有害信息
训练成本
- 计算资源:数千张 A100/H100 GPU
- 训练时长:数周到数月
- 资金成本:数百万到数千万美元
预训练后的能力
- ✅ 强大的语言生成能力
- ✅ 丰富的知识储备
- ❌ 不会遵循指令(你问"今天天气怎么样",它可能继续生成"明天呢?后天呢?")
- ❌ 回答格式不稳定
代表模型
- GPT 系列(GPT-3、GPT-4)
- LLaMA 系列
- Qwen 系列
- GLM 系列
第二阶段:监督微调(Supervised Fine-Tuning, SFT)
核心目标
让模型学会遵循人类指令,以问答的形式提供有用的回复。
训练方式
监督学习:使用高质量的"指令-回答"数据对进行训练。
训练数据
- 来源:人工标注的高质量问答对
- 规模:通常数万到数十万条(远小于预训练数据)
- 类型:
- 问答任务
- 内容生成
- 代码编写
- 摘要总结
- 翻译任务
- 推理问题
数据质量要求
SFT 数据质量至关重要,通常由专业标注团队创建:
- 回答准确、完整
- 格式规范、易读
- 覆盖多种任务类型
- 体现期望的行为模式
训练成本
- 计算资源:数十到数百张 GPU
- 训练时长:数天到数周
- 资金成本:数万到数十万美元
SFT 后的能力提升
- ✅ 会遵循指令
- ✅ 回答格式稳定(如:问什么答什么)
- ✅ 能完成特定任务(翻译、编程、总结等)
- ❌ 仍可能生成有害内容
- ❌ 仍可能编造事实(幻觉)
- ❌ 不一定符合人类偏好(可能冗长、无聊、啰嗦)
第三阶段:人类反馈强化学习(RLHF)
核心目标
让模型的输出更符合人类偏好:有用(Helpful)、无害(Harmless)、真实(Honest)。
RLHF 工作流程
步骤 1:收集人类反馈数据
- 给定一个问题,让模型生成多个候选答案(如 4 个)
- 人类标注员对这些答案进行排序:最好 → 最差
- 收集大量这样的排序数据
示例:
步骤 2:训练奖励模型(Reward Model, RM)
- 使用人类排序数据训练一个"打分器"
- 输入:问题 + 回答
- 输出:分数(越高越好)
这个奖励模型学会了"什么样的回答人类更喜欢"。
步骤 3:强化学习优化
使用强化学习算法(如 PPO)优化语言模型:
- 让模型生成回答
- 奖励模型打分
- 根据分数调整模型参数
- 目标:最大化奖励模型的分数
同时需要约束:
- 不能偏离 SFT 模型太远(避免模型"作弊"生成奇怪的高分回答)
- 使用 KL 散度惩罚项控制
RLHF 的技术挑战
- 奖励模型的准确性:RM 可能被"欺骗"
- 训练不稳定:强化学习本身就难训练
- 计算成本高:需要多次迭代
- 人类偏好的一致性:不同标注员的偏好可能冲突
RLHF 后的能力提升
- ✅ 回答更符合人类偏好(礼貌、友好、有条理)
- ✅ 减少有害内容
- ✅ 减少幻觉(通过人类反馈纠正)
- ✅ 更好的拒答能力(对不当问题说"不")
RLHF 的变体
-
Constitutional AI(Anthropic 提出,用于 Claude):
- 使用"宪法"(一组原则)代替部分人类反馈
- AI 自我批评和改进
-
DPO(Direct Preference Optimization):
- 直接从人类偏好数据优化,跳过奖励模型训练
- 简化流程,降低成本
-
RLAIF(RL from AI Feedback):
- 使用 AI 代替人类提供反馈
- 降低标注成本
三阶段对比
| 阶段 | 目标 | 数据规模 | 成本 | 训练时长 |
|---|---|---|---|---|
| 预训练 | 学习语言和知识 | 数万亿 token | 数百万美元 | 数月 |
| 监督微调 | 学会遵循指令 | 数万-数十万条 | 数十万美元 | 数周 |
| RLHF | 符合人类偏好 | 数千-数万条排序数据 | 数十万美元 | 数周 |
实际应用案例
ChatGPT 的训练流程
- 预训练:GPT-3.5 基础模型(1750 亿参数)
- SFT:使用人工标注的高质量对话数据
- RLHF:通过人类排序反馈优化
LLaMA 2 的训练流程
- 预训练:在 2T token 上训练(开源)
- SFT:使用公开指令数据集 + 自建数据
- RLHF:迭代多轮,发布 LLaMA 2-Chat
Claude 的训练流程
- 预训练:基础语言模型
- Constitutional AI:自我批评 + 人类反馈结合
- 持续优化:通过用户反馈不断改进
为什么要分三阶段?
预训练无法直接做 RLHF
- 预训练需要海量无标注数据,成本已经极高
- 人工反馈数据非常昂贵,无法支撑预训练级别的规模
SFT 是必要的中间步骤
- 直接从预训练到 RLHF 效果很差
- SFT 让模型先学会"基本礼貌",RLHF 再精修
RLHF 是最终打磨
- SFT 只能学到"平均答案"
- RLHF 学习"人类偏好",更细腻
常见问题
Q: 能跳过某个阶段吗?
A:
- 跳过预训练:不行,模型没有知识基础
- 跳过 SFT:理论上可以,但效果很差
- 跳过 RLHF:可以,但输出质量明显下降
Q: 普通开发者能做这些训练吗?
A:
- 预训练:几乎不可能(成本太高)
- SFT:可以!很多开源工具支持(如 Hugging Face TRL)
- RLHF:有一定门槛,但也有开源实现(如 trlX)
Q: 微调和 SFT 是一回事吗?
A: 不完全是。
- 微调(Fine-tuning)是广义概念,包括 SFT、领域微调、任务微调等
- SFT 特指"监督微调"这一特定方法
参考资料
- Training language models to follow instructions with human feedback - InstructGPT 论文(RLHF 经典)
- Constitutional AI: Harmlessness from AI Feedback - Anthropic 的 Constitutional AI
- Direct Preference Optimization - DPO 论文
- LLaMA 2: Open Foundation and Fine-Tuned Chat Models - LLaMA 2 论文
- 什么是 LLM 微调技术 - 本站相关文章
目录