✨ 新增内容 AI 共创
AI播客:Transformer核心:Encoder-Decoder模型为何仍是翻译首选?
💡 大白话解释 用最简单的话说清楚 ▶
什么是 Encoder-Decoder 架构 核心流程(以翻译为例):
输入中文:"我爱北京天安门"
↓
Encoder(编码器):
读取 → "我" "爱" "北京" "天安门"
理解 → "一个人表达对北京天安门的喜爱"
压缩 → 向量 [0.2, -0.5, 0.8, ...](数学表示)
↓
Decoder(解码器):
接收向量 [0.2, -0.5, 0.8, ...]
生成第 1 个词 → "I"
生成第 2 个词 → "love"
生成第 3 个词 → "Tiananmen"
生成第 4 个词 → "Square"
生成第 5 个词 → <结束>
↓
输出英文:"I love Tiananmen Square"
三种常见架构对比:
1. 纯 Encoder 模型(只负责"理解")
代表:BERT
任务:分类、问答、命名实体识别
例子:
输入:"这部电影很棒"
Encoder 理解 → [情感=正面]
输出:正面情感(分类结果)
2. 纯 Decoder 模型(只负责"生成")
代表:GPT-3、GPT-4、ChatGPT
任务:文本生成、对话、续写
例子:
输入:"从前有座山"
Decoder 生成 → ",山上有座庙"
3. Encoder-Decoder 模型(理解 + 生成)
代表:T5、BART、翻译模型
任务:翻译、摘要、问答生成
例子:
输入:"Please summarize: [长文]"
Encoder 理解长文 → [核心内容编码]
Decoder 生成摘要 → "文章主要讲..."
为什么需要 Encoder-Decoder?
问题:纯 Decoder(如 GPT)也能翻译,为啥还要 Encoder-Decoder?
答:效率 + 性能
纯 Decoder 翻译:
输入:"翻译成英文:我爱你"
模型:一边读输入,一边生成输出
问题:需要记住整个输入 + 生成的输出,上下文窗口浪费
Encoder-Decoder 翻译:
输入:"我爱你"
Encoder:先完全理解输入,压缩成向量
Decoder:只需基于向量生成输出
好处:
1. 输入和输出分离,效率高
2. Encoder 专注理解,Decoder 专注生成
3. 适合输入输出差异大的任务(如翻译)
实际应用:
1. 机器翻译
中文 → Encoder → [理解编码] → Decoder → 英文
"你好" → Encoder → [向量] → Decoder → "Hello"
2. 文本摘要
长文 → Encoder → [核心内容编码] → Decoder → 摘要
[5000 字文章] → Encoder → [向量] → Decoder → "本文讲..."
3. 问答生成
问题 → Encoder → [理解问题] → Decoder → 答案
"首都是哪?" → Encoder → [向量] → Decoder → "北京"
4. 代码转换
Python 代码 → Encoder → [逻辑编码] → Decoder → JavaScript 代码
Encoder 和 Decoder 的内部结构(Transformer):
Encoder(理解):
输入:"我爱你"
↓
词嵌入:["我", "爱", "你"] → [向量1, 向量2, 向量3]
↓
Self-Attention(自注意力):
- "我"关注"爱"和"你"
- "爱"关注"我"和"你"
- 理解三个词之间的关系
↓
前馈网络(FFN):
- 进一步处理
↓
输出:[理解向量](包含全句信息)
Decoder(生成):
接收 Encoder 的 [理解向量]
↓
生成第 1 个词:
- Self-Attention:看已生成的词(目前没有)
- Cross-Attention:看 Encoder 的理解向量
- 决定:生成 "I"
↓
生成第 2 个词:
- Self-Attention:看已生成的 "I"
- Cross-Attention:看 Encoder 的理解向量
- 决定:生成 "love"
↓
生成第 3 个词:
- Self-Attention:看已生成的 "I love"
- Cross-Attention:看 Encoder 的理解向量
- 决定:生成 "you"
↓
输出:"I love you"
关键:Cross-Attention(交叉注意力)
Decoder 通过 Cross-Attention "看" Encoder 的理解:
Decoder:"我现在要生成第二个词,Encoder 你说输入是啥意思?"
Encoder:"输入是表达爱意"
Decoder:"好,那我生成 'love'"
为什么 GPT 不用 Encoder-Decoder?
GPT 的设计哲学:
"万物皆生成"
所有任务都转化为"续写"
例如翻译:
输入:翻译成英文:我爱你\n英文:
GPT 续写:I love you
优点:
架构简单(只有 Decoder)
通用性强(一个模型搞定所有任务)
缺点:
T5 模型(Text-to-Text):
T5 是 Encoder-Decoder 的代表,把所有任务都转成"文本到文本" :
翻译:
输入:translate English to German: Hello
输出:Hallo
摘要:
输入:summarize: [长文]
输出:摘要内容
问答:
输入:question: 首都是哪? context: 中国的首都是北京
输出:北京
优点:
统一框架(所有任务用同一套架构)
Encoder-Decoder 效率高
实际选择:
任务 推荐架构 原因 翻译 Encoder-Decoder 输入输出差异大 摘要 Encoder-Decoder 需要先理解全文 对话生成 Decoder-only(GPT) 灵活,通用 分类/NER Encoder-only(BERT) 只需理解,不需生成 问答 Encoder-Decoder 或 Decoder-only 都可以 代码生成 Decoder-only 续写更自然
常见误区:
误区 1:"Encoder-Decoder 比纯 Decoder 好"
不对!看任务:
翻译、摘要:Encoder-Decoder 更好
对话、生成:纯 Decoder(GPT)更好
误区 2:"ChatGPT 是 Encoder-Decoder"
不对!ChatGPT 是纯 Decoder(GPT 架构)
只有一个 Decoder,没有独立的 Encoder
误区 3:"Encoder 和 Decoder 必须分开"
不对!有些模型(如 GPT)用同一套 Decoder 既理解又生成
Encoder-Decoder 只是一种设计选择
说白了,Encoder-Decoder 就是"翻译官"模型——Encoder 负责"听懂"输入,Decoder 负责"说出"输出。特别适合翻译、摘要这种"输入输出差异大"的任务。而 GPT 这种纯 Decoder 更像"续写高手",所有任务都当成"接龙游戏"。
预计阅读时间: 10 分钟
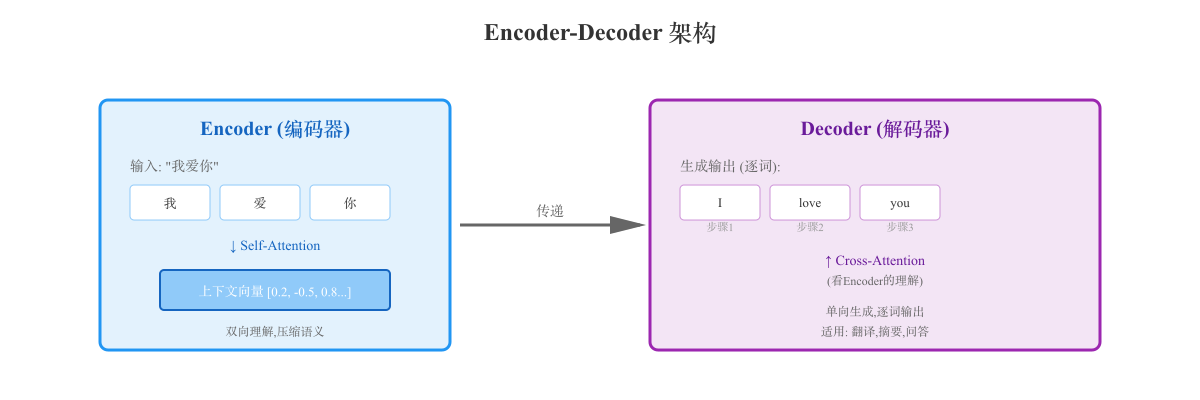
Encoder-Decoder 架构是深度学习中处理序列到序列(Sequence-to-Sequence, Seq2Seq)任务的经典模型结构。
它由两个核心组件组成:Encoder(编码器) 负责理解输入,Decoder(解码器) 负责生成输出。
核心概念
Encoder-Decoder 的设计思想
问题: 如何处理输入和输出长度/格式不同的任务?
示例任务:
机器翻译:"我爱你"(3 个词)→ "I love you"(3 个词,但语言不同)
文本摘要:1000 字文章 → 100 字摘要
问答系统:问题(10 个词)→ 答案(50 个词)
解决方案:Encoder-Decoder
输入序列 → Encoder(压缩理解)→ 上下文向量 → Decoder(展开生成)→ 输出序列
两个核心组件
Encoder(编码器):
功能:将输入序列压缩成固定长度的上下文向量 (Context Vector)
目标:捕捉输入的语义信息
输出:一个或多个向量,包含输入的"理解"
Decoder(解码器):
功能:基于 Encoder 的上下文向量,逐步生成输出序列
目标:根据理解,生成目标序列
输出:一个词一个词地生成(自回归)
工作流程
完整流程示意(翻译任务)
任务: 中文 "我爱北京" → 英文 "I love Beijing"
步骤 1:Encoder 处理输入
输入:"我" "爱" "北京" <EOS>
↓
词嵌入:[向量1] [向量2] [向量3] [结束向量]
↓
Self-Attention:
- "我"与"爱"、"北京"的关系
- "爱"与"我"、"北京"的关系
- "北京"与"我"、"爱"的关系
↓
前馈网络(FFN)处理
↓
输出:上下文向量 [C1, C2, C3](包含全句理解)
---
步骤 2:Decoder 生成输出
接收上下文向量 [C1, C2, C3]
↓
生成第 1 个词:
- 输入:<START> token
- Cross-Attention:查看 Encoder 输出 [C1, C2, C3]
- Self-Attention:查看已生成的词(目前只有 <START>)
- 输出:"I"
↓
生成第 2 个词:
- 输入:<START> "I"
- Cross-Attention:查看 [C1, C2, C3]
- Self-Attention:查看 "I"
- 输出:"love"
↓
生成第 3 个词:
- 输入:<START> "I" "love"
- Cross-Attention:查看 [C1, C2, C3]
- Self-Attention:查看 "I love"
- 输出:"Beijing"
↓
生成第 4 个 token:
- 输入:<START> "I" "love" "Beijing"
- 输出:<EOS>(结束标记)
↓
最终输出:"I love Beijing"
Encoder-Decoder 时序图
以下时序图展示了 Encoder-Decoder 架构在翻译任务中的完整交互过程:
关键机制:Cross-Attention(交叉注意力)
Decoder 如何"看到" Encoder 的信息?
通过 Cross-Attention :
Decoder(当前生成到 "I"):
Query(查询): 当前 Decoder 状态
Key & Value: Encoder 的所有输出 [C1, C2, C3]
计算注意力权重:
- C1("我"): 权重 0.6
- C2("爱"): 权重 0.3
- C3("北京"): 权重 0.1
加权求和:
输出 = 0.6*C1 + 0.3*C2 + 0.1*C3
Decoder 基于这个输出生成下一个词
为什么叫"Cross"?
"Cross"(交叉)= Decoder 的 Query 查询 Encoder 的 Key/Value
不同于 Self-Attention(自己查自己)
Transformer 中的 Encoder-Decoder
Encoder 的结构
单层 Encoder Block:
输入词嵌入
↓
Multi-Head Self-Attention
- 每个词关注所有其他词
- 理解词与词之间的关系
↓
Add & Norm(残差连接 + 层归一化)
↓
Feed-Forward Network(前馈网络)
- 对每个词独立处理
↓
Add & Norm
↓
输出到下一层
多层堆叠:
Transformer 原论文:6 层 Encoder
BERT:12 层(Base)或 24 层(Large)
T5:12-24 层
Decoder 的结构
单层 Decoder Block:
输入(已生成的词)
↓
Masked Multi-Head Self-Attention
- 只能看"左边"的词(已生成的)
- 不能"偷看"未来的词
↓
Add & Norm
↓
Multi-Head Cross-Attention
- Query: Decoder 当前状态
- Key & Value: Encoder 的输出
- "看" Encoder 的理解
↓
Add & Norm
↓
Feed-Forward Network
↓
Add & Norm
↓
输出到下一层
关键差异:
Masked Self-Attention :防止"偷看答案"Cross-Attention :连接 Encoder 和 Decoder
Transformer 架构全图
输入:"我爱北京"
↓
┌──────────────────┐
│ Encoder Stack │
│ (6 layers) │
│ │
│ Layer 1: │
│ - Self-Attn │
│ - FFN │
│ │
│ Layer 2: │
│ - Self-Attn │
│ - FFN │
│ ... │
│ Layer 6 │
└──────────────────┘
↓
上下文向量 [C1, C2, C3]
↓
┌──────────────────┐
│ Decoder Stack │
│ (6 layers) │
│ │
│ Layer 1: │
│ - Masked Self- │
│ Attention │
│ - Cross-Attn │ ← 看 Encoder
│ - FFN │
│ │
│ Layer 2: │
│ - Masked Self- │
│ Attention │
│ - Cross-Attn │
│ - FFN │
│ ... │
│ Layer 6 │
└──────────────────┘
↓
输出:"I love Beijing"
三种架构对比
1. Encoder-only(仅编码器)
代表模型: BERT, RoBERTa, ALBERT
结构:
适用任务:
文本分类(情感分析、主题分类)
命名实体识别(NER)
问答(抽取式)
文本相似度
示例:情感分类
输入:"这部电影很棒"
↓
BERT Encoder
↓
输出向量:[0.2, -0.5, 0.8, ...]
↓
分类层:Softmax
↓
结果:正面(概率 95%)
优点:
缺点:
2. Decoder-only(仅解码器)
代表模型: GPT-3, GPT-4, ChatGPT, LLaMA, Mistral
结构:
适用任务:
示例:续写
输入:"从前有座山"
↓
GPT Decoder(自回归生成)
↓
生成:",山上有座庙,庙里有个老和尚..."
优点:
生成能力强
架构简单(只有 Decoder)
通用性好(所有任务都是"续写")
缺点:
3. Encoder-Decoder(编码器-解码器)
代表模型: T5, BART, mBART, Pegasus, 翻译模型(如 Google Translate)
结构:
输入 → Encoder → 上下文向量 → Decoder → 输出
适用任务:
机器翻译
文本摘要
问答生成
数据到文本(表格 → 描述)
示例:摘要
输入:[3000 字长文]
↓
Encoder:理解全文
↓
上下文向量:[核心内容压缩]
↓
Decoder:生成摘要
↓
输出:"本文主要介绍了..."(200 字)
优点:
输入输出分离(适合长度差异大的任务)
Encoder 双向理解,Decoder 生成
效率高(先理解,再生成)
缺点:
对比表
特性 Encoder-only Decoder-only Encoder-Decoder 代表模型 BERT GPT-4 T5, BART 理解方式 双向 单向(从左到右) 双向(Encoder) 生成能力 弱 强 强 适用任务 分类、NER、问答 生成、对话 翻译、摘要 架构复杂度 低 低 高 训练效率 高 中 低
代表模型详解
T5(Text-to-Text Transfer Transformer)
核心理念: 将所有 NLP 任务统一为"文本到文本"
示例:
翻译:
输入:translate English to German: Hello
输出:Hallo
摘要:
输入:summarize: [长文]
输出:摘要内容
分类:
输入:sentiment: This movie is great!
输出:positive
问答:
输入:question: What is the capital? context: The capital of France is Paris.
输出:Paris
优点:
模型规模:
T5-Small:60M 参数
T5-Base:220M 参数
T5-Large:770M 参数
T5-3B:3B 参数
T5-11B:11B 参数
BART(Bidirectional and Auto-Regressive Transformers)
核心理念: 结合 BERT 的双向编码 + GPT 的自回归解码
预训练任务: 去噪自编码
原文:The quick brown fox jumps over the lazy dog.
破坏:The <mask> brown <mask> jumps <mask> the lazy <mask>.
任务:还原原文
适用任务:
模型规模:
BART-Base:140M 参数
BART-Large:400M 参数
mBART(Multilingual BART)
核心理念: 多语言版本的 BART
支持语言: 25+ 语言(中文、英文、法文、德文等)
应用:
实际应用案例
案例 1:机器翻译
Google Translate 使用 Transformer Encoder-Decoder
# 伪代码示例
from transformers import MarianMTModel , MarianTokenizer
# 加载中译英模型
model_name = "Helsinki-NLP/opus-mt-zh-en"
tokenizer = MarianTokenizer . from_pretrained ( model_name )
model = MarianMTModel . from_pretrained ( model_name )
# 输入中文
text = "我爱北京天安门"
inputs = tokenizer ( text , return_tensors = "pt" )
# Encoder-Decoder 翻译
outputs = model . generate ( ** inputs )
translation = tokenizer . decode ( outputs [ 0 ] , skip_special_tokens = True )
print ( translation ) # "I love Tiananmen Square in Beijing" 案例 2:文本摘要
使用 BART 摘要长文
from transformers import BartForConditionalGeneration , BartTokenizer
model = BartForConditionalGeneration . from_pretrained ( "facebook/bart-large-cnn" )
tokenizer = BartTokenizer . from_pretrained ( "facebook/bart-large-cnn" )
article = """
长文内容...(1000 字)
"""
# Encoder 理解全文,Decoder 生成摘要
inputs = tokenizer ( article , max_length = 1024 , return_tensors = "pt" , truncation = True )
summary_ids = model . generate ( inputs [ "input_ids" ] , max_length = 150 , min_length = 50 )
summary = tokenizer . decode ( summary_ids [ 0 ] , skip_special_tokens = True )
print ( summary ) 案例 3:问答生成
使用 T5 生成答案
from transformers import T5ForConditionalGeneration , T5Tokenizer
model = T5ForConditionalGeneration . from_pretrained ( "t5-base" )
tokenizer = T5Tokenizer . from_pretrained ( "t5-base" )
# T5 的输入格式
input_text = "question: What is the capital of France? context: France is a country in Europe. Its capital is Paris."
inputs = tokenizer ( input_text , return_tensors = "pt" )
# 生成答案
outputs = model . generate ( ** inputs )
answer = tokenizer . decode ( outputs [ 0 ] , skip_special_tokens = True )
print ( answer ) # "Paris" 为什么 GPT 不用 Encoder-Decoder?
GPT 的设计哲学
核心思想: "万物皆生成"——所有任务都转化为文本续写
翻译(Decoder-only 方式):
输入提示词:
Translate Chinese to English:
Chinese: 我爱你
English:
GPT 续写:I love you
摘要(Decoder-only 方式):
输入提示词:
Summarize the following article in 3 sentences:
[长文]
Summary:
GPT 续写:[摘要]
为什么选择 Decoder-only?
优点:
架构简单 :只有 Decoder,易于扩展到超大规模(175B+)通用性强 :一个模型处理所有任务训练数据丰富 :互联网上大量"续写"数据(文章、对话、代码)
代价:
上下文窗口压力大 :输入 + 输出都占用上下文翻译/摘要效率稍低 :需要"读一遍"输入再生成
结论:
对于通用 AI(如 ChatGPT),Decoder-only 更合适
对于专用任务(翻译、摘要),Encoder-Decoder 更高效
常见问题
Q: Encoder-Decoder 比 Decoder-only 更好吗?
A: 看任务:
翻译、摘要:Encoder-Decoder 更好
通用对话、生成:Decoder-only(GPT)更好
Q: 为什么 BERT 不能生成文本?
A:
BERT 只有 Encoder,没有 Decoder
Encoder 的 Self-Attention 是双向的(可以看未来的词)
生成时不能"偷看答案",所以无法生成
Q: Encoder-Decoder 的上下文向量是什么?
A:
一个固定长度的向量(如 768 维)
包含输入序列的"压缩理解"
Decoder 通过 Cross-Attention 访问这个向量
Q: Encoder-Decoder 比 GPT 慢吗?
A:
训练:慢(两个组件)
推理:看任务
翻译:可能更快(输入输出分离)
对话:GPT 更快(架构简单)
参考资料