新增内容AI 共创
AI播客:Transformer 为什么需要位置编码?解密并行计算的顺序难题
什么是 Position Encoding
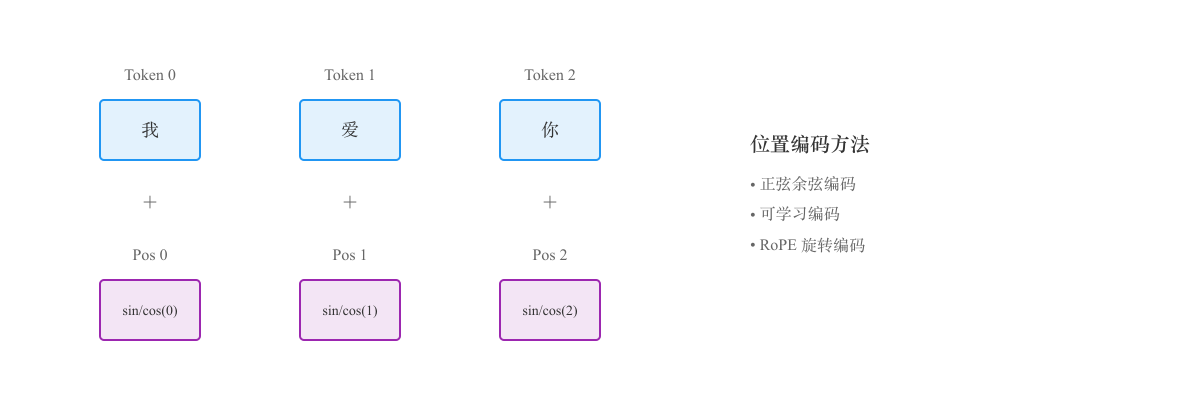
Position Encoding(位置编码)是 Transformer 架构中的关键组件,用于为输入序列中的每个 token(词元)添加位置信息。
由于 Transformer 使用自注意力机制并行处理所有 token,它本身无法感知 token 的顺序,因此需要显式地注入位置信息。
为什么需要位置编码?
预计阅读时间: 7 分钟传统的 RNN(循环神经网络)通过顺序处理输入,天然具备位置感知能力。但 Transformer 采用全并行计算:
- 优势:计算速度快,可充分利用 GPU 并行能力
- 问题:无法区分 token 的前后顺序
例如:
- "我爱你" 和 "你爱我" 在没有位置信息时,对 Transformer 来说是相同的输入
- Position Encoding 通过为每个位置生成唯一的向量来解决这个问题
位置编码的类型
1. 绝对位置编码(Absolute Position Encoding)
最直观的方法,直接为每个位置分配一个索引(0, 1, 2, 3...)。
经典实现:正弦-余弦位置编码(Transformer 原论文)
使用不同频率的正弦和余弦函数:
其中:
- :token 的位置(0, 1, 2...)
- :维度索引
- :模型维度
优点:
- 可以处理任意长度的序列(包括训练时未见过的长度)
- 不需要额外参数
- 通过三角函数的周期性,模型可以学习到相对位置关系
缺点:
- 对超长序列效果不佳
- 位置信息可能随着距离增加而衰减
2. 可学习位置编码(Learned Position Embedding)
将位置编码作为可训练参数,与词嵌入一样通过训练学习。
优点:
- 可以根据任务自适应学习最优位置表示
- 实现简单
缺点:
- 需要预定义最大序列长度
- 无法泛化到更长序列
代表模型:BERT、GPT-2/3
3. 相对位置编码(Relative Position Encoding)
不编码绝对位置,而是编码 token 之间的相对距离。
例如:"我 爱 你"
- 不记录"爱"在位置 1
- 而是记录"爱"在"我"后面 1 个位置,在"你"前面 1 个位置
优点:
- 更好的泛化能力
- 对序列长度变化更鲁棒
- 更符合语言的相对位置特性
缺点:
- 实现复杂度更高
- 计算开销更大
代表方法:
- T5 的相对位置偏置
- Transformer-XL 的相对位置编码
4. RoPE(Rotary Position Embedding,旋转位置编码)
当前最先进的位置编码方法之一,通过旋转操作注入位置信息。
核心思想:
- 将位置信息通过旋转矩阵融入到 Query 和 Key 向量中
- 使得不同位置的向量在高维空间中呈现旋转关系
优点:
- 同时具备绝对和相对位置信息
- 计算效率高
- 对长序列外推能力强
- 无需额外参数
代表模型:
- LLaMA 系列
- GLM 系列
- ChatGLM
- Qwen 系列
Position Encoding 的实际应用
在 Transformer 中的使用
位置编码与词嵌入相加,共同作为 Transformer 的输入。
长上下文扩展
现代 LLM 通过改进位置编码来支持更长的上下文:
- ALiBi(Attention with Linear Biases):通过在注意力分数中添加线性偏置
- xPos:改进的旋转位置编码,支持超长序列
- YaRN:通过缩放 RoPE 频率来扩展上下文窗口
例如,Qwen3 通过 Dual-Chunk Attention 和改进的 RoPE 实现了 1M token 上下文窗口。
位置编码的选择建议
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 固定长度任务 | 可学习位置编码 | 简单高效 |
| 变长序列 | 正弦-余弦编码 | 可泛化到任意长度 |
| 需要相对位置 | 相对位置编码 | 更好的语义理解 |
| 现代 LLM | RoPE | 综合性能最优 |
| 超长上下文 | ALiBi / xPos | 专为长序列设计 |
常见问题
Q: 为什么不直接用简单的整数编码(1, 2, 3...)?
A: 简单整数编码会导致:
- 位置值随序列增长而无限增大
- 不同位置的数值范围差异过大,影响训练稳定性
- 模型难以泛化到未见过的长度
Q: 位置编码会增加多少计算成本?
A:
- 绝对位置编码:几乎无额外成本(加法操作)
- 相对位置编码:增加约 10-20% 的注意力计算成本
- RoPE:增加约 5-10% 的计算成本
Q: 可以不用位置编码吗?
A: 对于某些特殊任务(如集合操作、无序数据处理)可以不用。但对于 NLP 任务,位置信息至关重要。
参考资料
- Attention Is All You Need - Transformer 原论文
- RoFormer: Enhanced Transformer with Rotary Position Embedding - RoPE 原论文
- Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation - ALiBi
- 什么是 Transformer - 本站相关文章
- Qwen3 扩展到 1M 上下文是如何做到的? - 本站相关文章
目录