AI播客:多头注意力:Transformer如何从多角度理解信息
什么是 Multi-Head Attention?
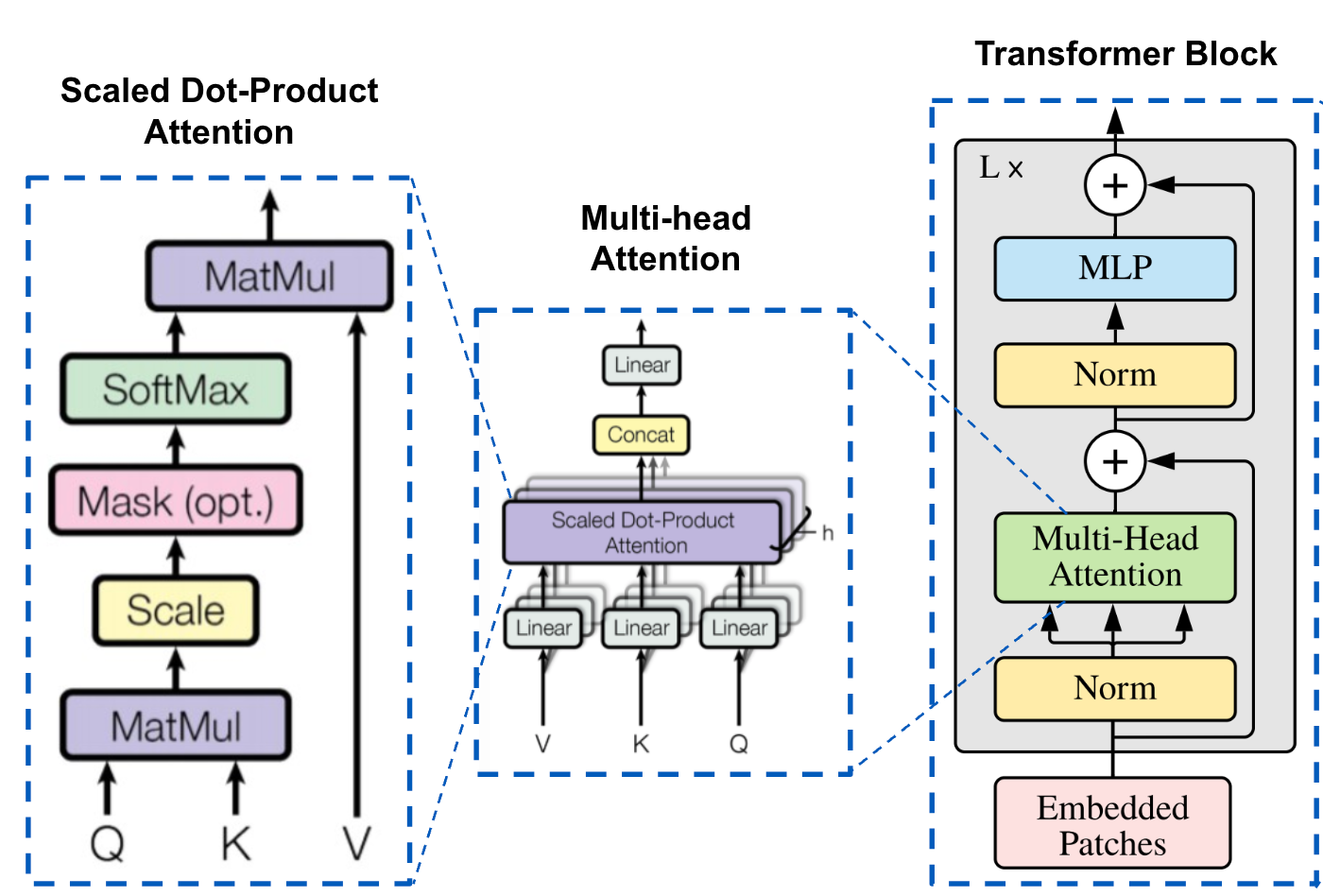
多头注意力(Multi-Head Attention)是 Transformer 架构中的一个核心组件,它通过并行运行多个注意力机制来增强模型的性能。
在多头注意力机制中,"头"是指一个独立的注意力机制。每个头有自己的一组权重,用于计算输入的自注意力。通过使用多个头,模型可以从不同的角度和特征空间中提取信息。
工作原理
预计阅读时间: 4 分钟
首先我们来看注意力公式, 给定输入向量 Q(查询)、K(键)和 V(值),注意力机制的计算公式为:
Attention(Q,K,V)=softmax(dkQKT)V
其中,dk 是K (键) 向量的维度。
多头注意力则将上面的公式拆分, 通过多个独立的注意力头来增强模型的能力。每个头有自己的查询、键和值的线性变换。公式如下:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中每个 headi 计算为:
headi=Attention(QWiQ,KWiK,VWiV)
WiQ,WiK,WiV,WO 是学习到的参数矩阵。
多头注意力机制将输入分成多个"头",每个头独立地执行自注意力计算,然后将所有头的输出合并起来。每个头可以关注输入序列的不同方面,从而捕获更丰富的特征信息。
核心机制
- 维度拆分:将输入向量维度 dmodel 通过线性投影拆分为h个dk维度(dk = dmodel/h),每个头关注不同的特征子空间
优点
- 并行计算优化:虽然总计算量(FLOPs)与单头注意力相同,但拆分后的多个小矩阵乘法(尺寸h×dk)更适配GPU并行计算特性 (当然实际 FLOPs 消耗会略高于单头,因为增加了投影矩阵计算)
缺点
-
内存/计算开销:每个头需要独立的 Q/K/V 投影矩阵,参数数量随头数线性增长:
输入投影3hdkdmodel+输出投影hdkdmodel=4hdkdmodel
其中:
- 输入投影:每个头包含 WiQ,WiK,WiV∈Rdmodel×dk 三个矩阵,共 3hdkdmodel 参数
- 输出投影:合并矩阵 WO∈Rhdk×dmodel,贡献 hdkdmodel 参数
- 当采用标准配置 dk=dmodel/h 时,总参数量简化为 4dmodel2(与头数无关)
-
键值缓存瓶颈:自回归解码时每个头需要独立缓存 K/V 矩阵,显存占用为 2bdmodelL(b=batch_size, L=seq_len)
-
信息冗余:实验表明不同头可能学习到相似的注意力模式(尤其在后层),造成计算资源浪费
-
工程复杂度:多头并行计算需要精细的内存布局管理,在长序列场景下容易导致内存带宽瓶颈
与 MQA/GQA 的对比
| 特性 | Multi-Head (MHA) | Multi-Query (MQA) | Grouped-Query (GQA) |
|---|
| 键值投影共享 | 无 | 所有头共享同一 K/V 投影 | 分组内共享 K/V 投影 |
| 参数量 | 4hdkdmodel | hdkdmodel+2dkdmodel | (h+2g)dkdmodel |
| 解码显存占用 | 高 | 极低(1/h) | 中等(g/h) |
| 模型容量 | 最高 | 最低 | 可调节(通过分组数 g) |
| 典型应用场景 | 编码器 | 低内存推理场景 | 质量与效率的平衡点 |
后续我们会逐一介绍多头注意力的优化版本 MQA/GQA 的原理和实现.
Refs